Data Infrastructure 101 para Product Data Managers
Um erro que cometi no começo da minha trajetória como Product Data Manager: confundir “entender infraestrutura” com “conseguir tomar todas as decisões de arquitetura sozinho”. A realidade é mais frágil que isso. Você não precisa ser capaz de configurar um cluster Elasticsearch, mas precisa entender o suficiente para reconhecer quando está sendo vendido algo impossível e quando as promessas de engenharia têm fundamento ou não. O risco contrário também existe: ser um PM tão passivo que a engenharia não consegue explicar constraints reais porque você não fala a linguagem mínima. A maioria das frustrações entre PMs e engenheiros vem de um lado propor features sem entender viabilidade, e o outro recusar tudo sem conseguir explicar o por quê.
Essa compreensão tem um propósito específico: reconhecer onde estão os trade-offs reais e ser capaz de negociar deles com a engenharia de forma honesta. A maioria dos PDMs em empresas brasileiras não conseguem fazer isso porque literalmente não veem a complexidade. O resultado é frustração bilateral: o PDM acha que engenharia é lenta, engenharia acha que PDM não entende o problema. Aqui vai o que você precisa ver para sair dessa armadilha.
O Fluxo Invisível de Dados
Antes de entrar em tecnologias específicas, entenda que dados não são um “recurso”. São um fluxo com pontos críticos onde as coisas quebram. O diagrama abaixo mostra o trajeto:
Fonte de Dados Extração Armazenagem Transformação Consumo Usuário
(messy) ————————→ (bruto) ————————→ (raw) ————————→ (processado) ————————→ (decisão)Fluxo de Dados com Pontos de Falha
Teoricamente, você deveria ter expectativas realistas e métricas de monitoramento em cada ponto. Na prática, a maioria das empresas brasileiras monitora apenas o “produto final” (o dashboard) e descobre problemas de upstream quando o usuário reclama. Um PDM que consegue conversar sobre esses pontos de falha com engenharia consegue negociar onde monitorar e qual nível de alerta faz sentido dados os recursos disponíveis.
Camada 1: Ingest — De Onde Vêm os Dados (E Por Que Tudo Quebra)
Você vai ouvir “vamos conectar a API do X” como se fosse trivial. Não é. Cada fonte de dados é um projeto. Uma API externa (Shodan, RiskRecon, GreyNoise) tem características que determinam toda a sua estratégia: rate limits (você pode fazer 1000 requisições por hora ou 10?), histórico disponível (consegue puxar dados de 2022 ou só últimos 30 dias?), completude (a API sempre retorna os mesmos campos ou às vezes um novo aparece?), e variabilidade de latência (uma requisição leva 100ms ou às vezes 30 segundos?).
Se você assinar um produto de dados que depende de uma API com rate limit de 100 req/hora, e sua demanda cresce para 500 req/hora, você tem um problema. Não é uma feature request fácil. É uma negociação com o fornecedor ou uma redesign da estratégia de caching. Essa é a realidade que a maioria dos PDMs não vê até é tarde demais.
Na prática em 2026, a maioria dos casos no Brasil usa pull via webhook + polling periódico. Você faz requisições durante o dia (pull) e tem webhooks notificando mudanças críticas (quasi-push). Dessa forma você controla a carga e não é refém de um terceiro. Pull puro (sua equipe extrai quando quer) te dá máximo controle mas você é responsável por monitorar falhas e ninguém sabe até manhã se algo quebrou. Push puro (a fonte empurra dados) oferece quase real-time mas você recebe o que eles querem enviar e se sobrecarregar podem throttle você ou desconectar.
Quando a engenharia disser “vamos conectar o Salesforce”, você deve perguntar: qual é o RTO (Recovery Time Objective) — em quanto tempo precisamos de alerta se a fonte parar? Qual é o RPO (Recovery Point Objective) — se a fonte falhar 6 horas, perdemos dados ou conseguimos recuperar? É idempotente — se falhar e rodar novamente, duplica dados? Qual é o SLA de freshness — dados de que horário são aceitáveis? A maioria das empresas brasileiras não mapeia isso. Depois, quando o produto lança e alguém pergunta “por que o dashboard de ontem não aparece?”, ninguém sabe a resposta. Porque nunca definiram qual era a expectativa.
Diagrama de Ingestão com SLOs

Storage — O Tesouro Está Onde?
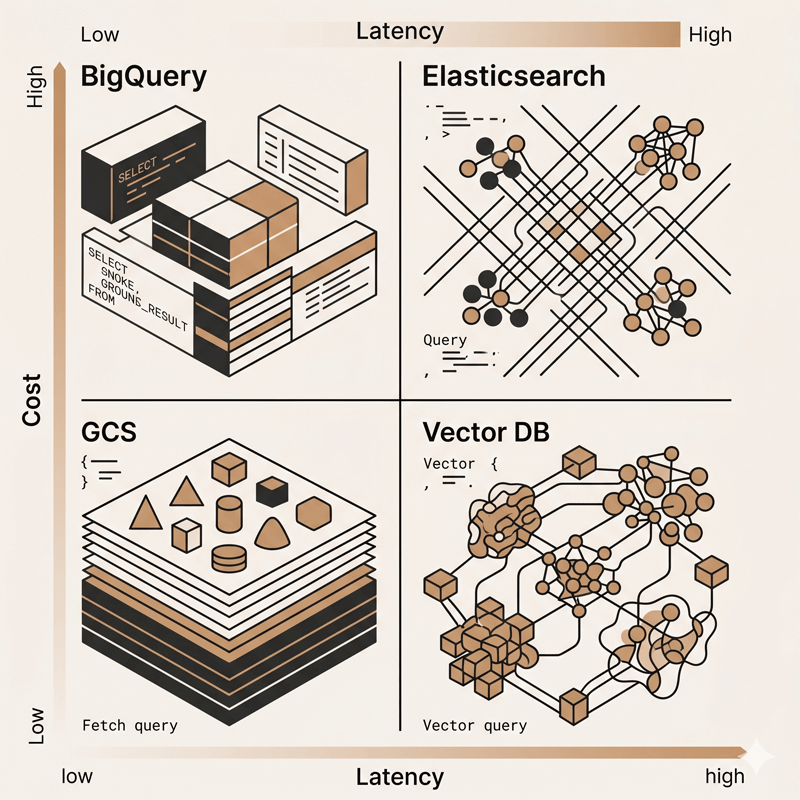
Aqui é onde a maior parte do budget de infraestrutura vai e onde a maioria dos PDMs faz pressupostos errados. A maldição da escolha é real: você pode guardar dados em BigQuery, Data Lake (GCS), Elasticsearch, Qdrant, PostgreSQL, MongoDB. Qual é o certo? Resposta incômoda: não existe “banco de dados bom” em abstrato. Existe o banco que resolve seu problema específico com seu volume específico.
Data Warehouse (OLAP) — BigQuery, Snowflake, Redshift. Otimizado para ler bilhões de linhas, agregar colunas, calcular médias/somas. Péssimo para buscar uma linha específica rápido ou atualizar um campo em tempo real. A pergunta “qual foi a taxa de crescimento de CVEs críticas por setor nos últimos 12 meses?” é perfeita pra warehouse — exige ler muitas linhas, agregar, calcular. Mas “me mostra a linha 5 bilhões da tabela” vai fazer full table scan, lento e caro. BigQuery cobra por dados scaneados: 1GB = ~$6.25, então um query ruim que scanneia 1TB inteiro por engano custa $6250. É uma bomba relógio esperando pra explodir no seu orçamento.
Data Lake (Raw Storage) — GCS, S3. Otimizado para guardar dados brutos a custo mínimo, agnóstico de estrutura. Custo típico é ~$0.02 por GB/mês, então 1TB = $20/mês. Muito mais barato que warehouse. O trade-off: você paga caro em “compute” quando quer ler esses dados. Um query em GCS é mais lento que em BigQuery porque não está indexado. Faz sentido quando você quer guardar “tudo” (full backups, logs brutos) por compliance ou future-proofing, mas não consultará frequentemente.
Search Engine — Elasticsearch, OpenSearch. Otimizado para encontrar um padrão de texto em bilhões de registros em <500ms. Péssimo para calcular agregações complexas ou fazer joins. A pergunta “ache todos os eventos que mencionem o IP 203.0.113.5 nos últimos 30 dias” é ouro puro — Elasticsearch indexa e procura no índice, não em cada linha. Mas caro em armazenamento (mantém índices na memória): um cluster pequeno = ~$500/mês, um médio = ~$3k/mês.
Vector DB — Qdrant, Pinecone, Weaviate. Otimizado para semântica. Você armazena “embeddings” (vetores que representam significado). A pergunta “ache documentos sobre ‘ransomware em hospitais’, mesmo que essas palavras exatas não estejam no documento” resolve bem. Novo demais pra ser ubíquo, mas é onde o market está indo rápido.
Na Tempest, operamos com múltiplos storages: BigQuery armazena histórico completo de 70+ collectors (5 anos de dados, $2k/mês), Elasticsearch guarda últimos 30 dias para buscas textuais rápidas ($1.8k/mês), GCS armazena backups brutos não tocados (~$100/mês). Total: $4k/mês de storage. Você poderia fazer tudo em BigQuery por ~$2.5k/mês, mas aí a busca de um analista que precisa encontrar “aquele evento de ontem com padrão XYZ” levaria 30 segundos em vez de 0.1 segundos. A pergunta de PDM é: vale pagar 60% a mais de custo de infraestrutura pra reduzir tempo de busca? Se o analista faz 50 buscas por dia, estamos economizando ~1.5 horas por dia de tempo dele. Se o custo/hora é alto (é threat intel, é caro), a resposta pode ser sim. Problema: a maioria dos PDMs não faz essa conta. Só sabem que “Elasticsearch custa caro” e cortam.
Matriz de Storage por Use Case
Processing — A Linha de Montagem e Seus Padrões
Esse é o lugar onde dados brutos viram produtos consumíveis. A revolução aqui é a transição de ETL (Extract, Transform, Load — transforma antes de guardar) para ELT (Extract, Load, Transform — guarda primeiro, transforma depois). ELT venceu porque é mais escalável: você não precisa de um “pipeline mágico” que resolve tudo. Você joga tudo no warehouse e transforma lá dentro.
Batch vs. Stream é uma decisão que ninguém faz bem. Batch (roda uma vez por dia ou a cada hora) tem latência de 24 horas (seu dashboard mostra dados de ontem), custo baixo (você roda uma vez), confiabilidade alta (se quebrar, você tem logs claros pra debugar). Stream (processa conforme o dado chega) tem latência <1 segundo, mas custo altíssimo (você paga infraestrutura 24/7, mesmo à noite quando ninguém usa) e confiabilidade baixa (muito mais complexo, muitos pontos de falha). A verdade que ninguém fala: 90% das empresas que “precisam de stream” na verdade só precisariam de batch com SLA de 1-2 horas. Elas escolhem stream por vanity (“real-time é cool”) e pagam 5-10x mais em infraestrutura por um ganho de 23 horas que ninguém percebe.
Batch vs Stream Trade-off Matrix
Na Tempest, processamos threat intelligence em batch diário (dbt roda à noite). Por quê? Um analista consultando dados de 12 horas atrás não sofre. Mas um alerta de “novo zero-day descoberto” precisa ser visto em <1 minuto (isso é stream + Elasticsearch, não batch). Essa é a distinção que a maioria das organizações não consegue fazer: nem tudo precisa de velocidade igual.
A maior mudança nos últimos 5 anos é dbt e a ideia de “transformações como código”. Antes: um analista abria BigQuery, escrevia uma query SQL, a copia/cola em um Excel todo mês. A query vira legend: ninguém sabe se está correta. Agora: a query é um arquivo .sql no Git. Tem testes. Tem documentação. Tem histórico de quem mudou o quê. Se alguém muda a regra de negócio, o PDM aprova no PR antes de ir pra produção. Isso não é só “bom practice”. É fundamental pra produto escalável. Porque agora você tem um contrato: “CVES_por_setor é definido como X, não como Y. Se mudar, precisa do PDM e do analista concordarem”.
Querying — Como Os Dados Saem
Parece trivial, mas é onde muitos produtos morrem. O mesmo dado pode ser acessado de 10 formas diferentes, e cada uma tem trade-offs. SQL Direto oferece máxima flexibilidade (um analista que sabe SQL consegue responder qualquer pergunta) mas alto risco operacional (alguém roda SELECT * em 10 bilhões de linhas e o bill explode) e privacidade (acesso irrestrito a dados sensíveis).
BI Tools (Metabase, Looker, Tableau) escondem complexidade (executivo não-técnico consegue abrir dashboard e ver resposta) mas são limitados (se pergunta não está no dashboard, resposta demora). APIs REST/GraphQL são integráveis (outro sistema pode consumir dados programaticamente) mas requerem versionamento (se você muda um campo, aplicações quebram).
RAG / LLM Conversacional é promissor, mas com armadilhas maiores do que promessas. A ideia: você armazena embeddings dos seus dados (vetores que representam significado), o usuário faz uma pergunta em linguagem natural, o sistema busca os documentos mais “semanticamente próximos”, passa pro LLM como contexto, e o LLM responde. A venda é “qualquer pessoa consegue fazer perguntas sem aprender SQL”. A realidade: se a busca vetorial retornar o documento errado, o LLM não sabe que está mentindo. Ele vai responder com confiança absoluta uma informação falsa. É pior que ter nenhuma resposta, porque o usuário acredita.
Há um segundo problema: RAG é excelente para perguntas exploratórias sobre documentação (“qual é o processo de onboarding?”), mas é péssimo para números críticos (“quanto faturamos em abril?”). Se você misturar os dois no mesmo produto, o usuário nunca sabe se deve confiar a resposta ou não. Na prática em 2026, RAG é uma feature legal pra exploração de dados internos (documentos, wikis, onboarding). Não é substituição para SQL+BI para decisões críticas.
UX/Produto — Onde a Confiança Vive ou Morre
Toda a infraestrutura invisível só importa no momento da verdade: quando o usuário abre o dashboard. Três métricas invisíveis para engenharia, mas vitais para produto: Time to Value (TTV) — quanto tempo depois que um dado entra na camada 1, ele aparece na tela do usuário? Se você recebe um evento de “novo zero-day descoberto” e ele leva 24 horas pra aparecer no dashboard, você perdeu o tempo de resposta. Na Tempest, um evento de threat intel entra em APIs externas → é puxado no polling de 1h → é processado em batch à noite → aparece em LUMINA no próximo dia. TTV: 24-25 horas. Pra reduzir, você precisaria fazer stream + Elasticsearch (custo +2x).
Reconciliação de Dados (Confiança) — Se o dado de “faturamento total” no BigQuery diz R$ 100k, mas o SAP operacional diz R$ 105k, qual você acredita? Se você não consegue responder essa pergunta com confiança, o usuário desconfia de tudo. Solução: ferramentas de Data Quality (Monte Carlo, Great Expectations, dbt tests) que checam completude (todas as linhas esperadas chegaram?), accuracy (valores estão no range esperado?), freshness (dado é novo o suficiente?). Você precisa de dashboards de “Data Quality Status” tão visíveis quanto o dashboard de negócio.
Observabilidade do Produto — Quando algo quebra, como o usuário avisa você? Resposta ruim: eles descobrem quando tentam usar (“por que o dashboard está em branco?”). Resposta boa: você tem alertas automáticos que disparam antes do usuário notar. Isso é a diferença entre ser reativo e proativo.
Estudo de Caso: LUMINA — Arquitetura Negociada
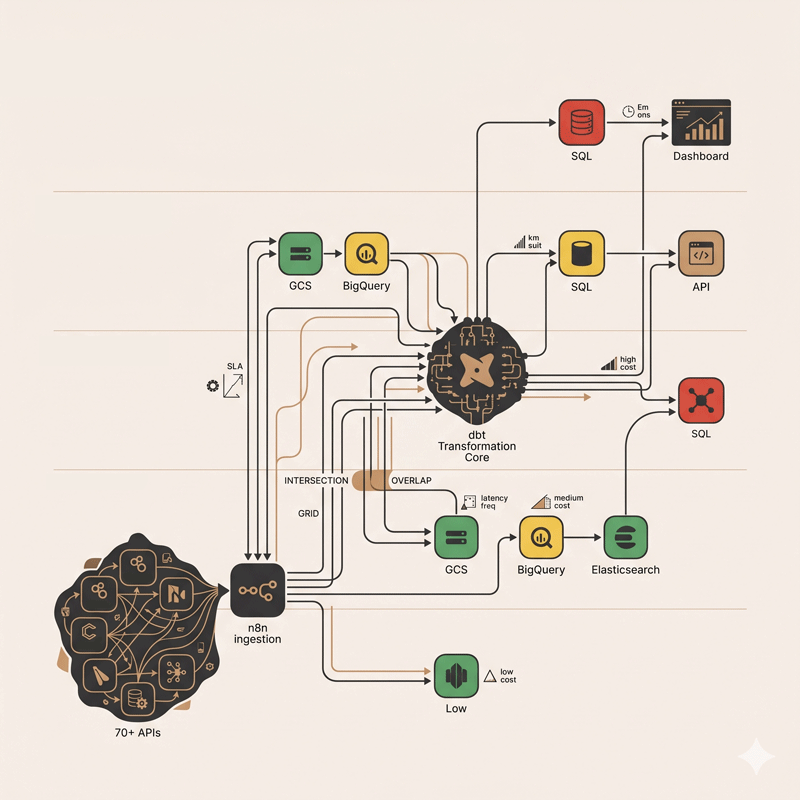
LUMINA é nosso observability tool para 70+ collectors de threat intelligence. A arquitetura abaixo é o que conseguimos acordar entre PDM (eu), engenharia e os constraints orçamentários reais:
Ingest (1h de latência): n8n orquestra 70+ APIs → puxa a cada hora
Storage (múltiplo): GCS (raw) + BigQuery (histórico) + Elasticsearch (search recente)
Processing (batch): dbt roda diariamente com testes, transformações modeladas como código
Querying (múltiplo): SQL direto + Elasticsearch DSL + API interna
UX: Dashboard customizado + Alertas (Email/Slack)Arquitetura Detalhada
n8n em vez de Airflow: Airflow exige um engenheiro dedicado. n8n é mais operável por um time menor. Trade-off: menos observabilidade granular, menos flexibilidade em lógica complexa. Verdict: pra 70 conectores simples (poll + store), n8n ganha.
BigQuery + Elasticsearch (não só um): Rodei a mesma query de busca em ambos. BigQuery: 30 segundos (full table scan). Elasticsearch: 0.1 segundos (índice). Um analista faz ~50 buscas por dia. Diferença: 25 minutos economizadas por dia. Custo adicional: ~$1.8k/mês em Elasticsearch. ROI: Se salário do analista é R$ 10k/mês (~R$ 50/hora), estamos economizando ~R$ 21k/ano em tempo dele por R$ 21.6k de infra. Break-even em 1 ano, depois lucro puro.
dbt em vez de scripts soltos: Transformações ficam versionadas, testadas, documentadas. Uma mudança em “o que é CVE crítica” precisa de PR review (PDM ou analista sênior aprova). Evita: discrepâncias entre “a definição que nós achávamos” e “a definição que engenharia implementou”.
Batch em vez de Stream: TTV é 24h. Um zero-day descoberto é visto no dia seguinte. Se precisássemos <1h, custaria 3x mais. Pergunta de PDM: “qual é o custo de negócio de esperar 24h?” Resposta: “praticamente zero, porque nossos clientes consultam LUMINA no início do dia”. Logo: batch é suficiente.
O Checklist de PDM (Diagnóstico de Saúde)
Quando você assumir um produto de dados, não pergunte sobre servidores. Sobre Ingest: o que acontece se a fonte primária para? Temos alertas automáticos? Em quanto tempo alguém é notificado? Qual é o SLA de “freshness”? Sobre Storage: qual é nosso “source of truth”? Qual é o custo projetado se volume triplicar no próximo ano? Estamos armazenando dados que nunca usamos? Sobre Processing: transformações têm testes? Se alguém muda uma regra, testes quebram? Qual é o plano de rollback de um pipeline quebrado? Documentamos por que cada transformação existe, ou só como? Sobre Querying & UX: existe documentação acessível para usuário final? Como medimos confiança nos dados? Existe painel de “Data Quality Status”? Quando algo quebra, usuário fica sabendo ou descobre quando tenta usar?
Se você não conseguir responder a maioria dessas perguntas com confiança, sua infra é frágil. A vulnerabilidade não é necessariamente uma bomba relógio esperando pra explodir, mas é um ponto de stress que se vai materializar quando menos espera.
Health Check Dashboard de Data Infrastructure]

Observação Final: O Que Realmente Importa
O ponto dessa leitura não é você virar engenheiro. É você conseguir ter conversas úteis com engenharia quando arquitetura é proposta. Um PDM que entende que “Elasticsearch custa 60% a mais mas reduz latência de 30s pra 0.1s, economizando 25 min/dia de tempo do analista = break-even em 1 ano” consegue defender uma decisão com números. Um PDM que só sabe “Elasticsearch é caro” fica refém de quem grita mais alto na sala.
Seu trabalho é garantir que a infra construída serve o melhor produto possível dentro dos limites reais (orçamento, capacidade técnica, tempo de mercado). Não é construir a solução perfeita em abstrato. É fazer a melhor decisão possível com as informações e recursos que você tem hoje.